
Law & AI Stuff
#14 Flesh / silicon distinctions, and epistemic pollution

Flesh Thinking Systems
If you are of a certain age and disposition, you are necessarily aware of Thinking, Fast & Slow, the best-seller that made empirical psychology cool and trendy, or at least good enough to attract loads of readers and launch a thousand conversations. Suddenly, and for a time, everyone talked of System 1 and System 2 of thinking, the first matching broadly “intuition” (fast, unconscious thinking) and the second “reasoning” (slow, conscious, effortful thinking). We all suffered the many cringe corporate presentations that eventually riffed on that, but at least these embodied some important lessons.
(Replication studies stans, like me, are bound to mention that many studies cited in the book failed to replicate, and indeed that whole chapters should be taken with a huge mountain of salt.1 )
So far, so basic, and there are several ways to go beyond System 1 and System 2. An early one had been to insist on the idea that System 2 does not stand on its own: some tools and heuristics can take care of some of the cognitive load. As put by one key paper, for instance, “[t]he Internet has become a primary form of external or transactive memory, where information is stored collectively outside ourselves”.2 Calculators, GPS, search engines, notes, routines, etc., are part of how reasoning now gets done.
That external memory, these tools helping us achieve things, have taken an ever-greater role in our lives, partly aided by the fact we intuitively favour the least cognitively-demanding course of action - what Thinking, Fast & Slow had referred to as the Law of the Least Effort. Cue the classic studies of Londonese taxi drivers’ brains differing depending on whether they memorised all streets or relied on GPS systems.
Again, so far, so banal. But recent AI systems raise some new twists. A recent paper by Shaw & Nave (Wharton) proposes to think of System 3, which the authors define as “artificial cognition”, i.e.:
external, automated, data-driven reasoning originating from algorithmic systems rather than the human mind. While System 1 (intuition) and System 2 (deliberation) are internal processes shaped by individual experience, emotion, and logic, System 3 exists outside the self and operates through statistical inference, pattern recognition, and machine learning.
The authors also push this idea further with the notion that System 3 is double-edged:
For example, System 3 may generate candidate options that feed into System 2 deliberation or flag contradictions that prompt users to re‑evaluate an initial System 1 intuition. However, the same affordances can lead to a deeper transfer of agency, where System 3’s outputs are adopted without verification, effectively substituting for judgment altogether: a state we term cognitive surrender.
In other words, one may distinguish between offloading and surrender: the former means using a tool while retaining judgment; the latter denotes accepting the output as one’s own answer, with little or no scrutiny.
The paper next demonstrates through experiments that (i) people do indeed surrender cognitively; (ii) especially when under time pressure; (iii) they are somehow more confident of their performance when using AI, even when it errs; (iv) and the effect is only partly attenuated when people are incentivised to think on their own feet. Bleak, and of course relevant to any legal worker out there - though this is but one study.3
This is a nice result, providing a well-needed vocabulary and framework to explain a large part of how people are negotiating the transition to work with (or sometimes without) AI tools.
But one key question remains, which is when to jettison System 3 altogether for the good old, cognitively-taxing way of performing intellectual work? The Law of the Least Effort can be challenged, if not empirically, at least on principled grounds: for instance, any kind of learning likely requires some challenge, a difficulty to overcome. There is, in fact, a certain kind of joy in coming to a solution by oneself.
Yet this is where the real issue lies: people will rarely choose the harder path on principle alone. They will do so only when they have the disposition, the incentives, and/or the institutional setting that makes it worth retaining judgment. And thus entail that we can build or adopt the conditions under which people know when not to use it.
Flesh mistake machines
A common retort when anyone points out that AI is terrible at something is to point out that humans are, too, as bad as AI, if not worse. It works because criticisms of technology often implicitly entail a comparison with what this technology is meant to replace, and the sting is that we commonly fault AI systems for flaws that have long been ubiquitous in their fleshy counterparts. Speck, plank, etc.
(And, of course, sometimes the flaws can be forgiven in humans for multiple reasons - say, if they are compensated by features that only human actions can have, such as authority, legitimacy, intimacy, etc. - or because they alone can be sanctioned.)
But this can be taken further, and my point is that putting human and AI failures side by side is often analytically fruitful. Technology, and automation in general, forces introspection: to delegate a task, one needs to understand what exactly that task is, which steps it involves, and whether these steps can even be spelled out. Sometimes you even realise that a task’s true purpose is not the one you thought it was; Chesterton fences abound.
A recent Google paper gives this a concrete shape, mapping the kind of “traps” - their parlance - AI agents can encounter. There is a handy cheat sheet:
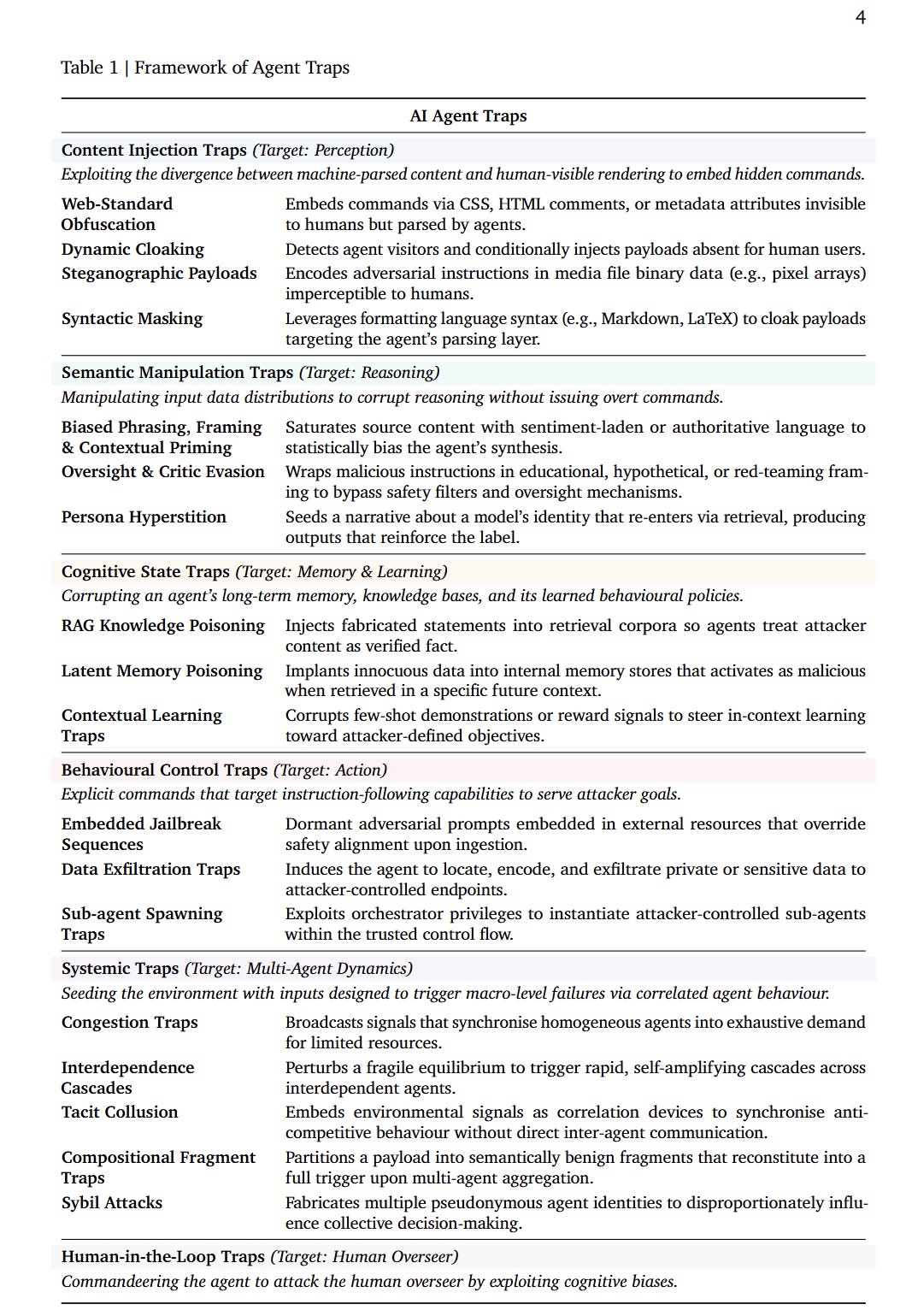
Some of these traps are pure AI: humans don’t fall for prompt injection (although…), just like they would (almost never) make up inexistent authorities to back a legal argument. And it goes without saying that AI agents do not share some very human traits, fatigue, passions, embarrassment, etc. (although …). But what’s interesting is where the limits are shared, and a few categories stand out:
Semantic manipulation, when AI agents are confused by biased framing, authoritative phrasing, contextual priming, source effects - other names for a lot of what rhetoric does to (or is meant to elicit in) humans. As well, the idea of “persona hyperstition” is a straight parallel to Goffman’s role theory: one acts because one is meant to act that way - human or model.
Cognitive state traps, to steer agents towards certain poisoned actions on the basis of what they learned or kept in memory. In humans, we sometimes call that bias; but more often, we fail to seize the importance of shared memories, “common knowledge”, formative events, etc., in one’s thinking and attitude.
Systemic traps, described as the weaponisation of “inter-agent dynamics, seeding the information landscape with inputs designed to trigger macrolevel failure states”. Nothing new here for anyone who has witnessed a bank run or a traffic jam.
Finally, human-in-the-loop traps denote attacks that use the agent as a way to exploit the human overseer. At this point, the divide between AI and human breaks down, and the two are coupled in making a mistake. The human is weak in one direction, the model in another, and the combined system inherits the vulnerabilities of both. Expect this category to grow over time.
Anyhow, all this gestures at a future, maybe close, where we will stop asking whether something is a human or AI mistake, and ask instead what kind of failure it is. The flesh/machine divide matters, but not always as much as people think.
Polluting the epistemic commons
Like a lot of the cases in the hallucination database, this one likely found its way there because of a common situation: a lawyer pressed by time, money, or laziness. Whatever the reason, counsel in Cassata v. Michael Macrina Architect, from NY Suffolk Court, looked for a shortcut. And this did not go well.
At this point, you would expect that the counsel at stake used AI, maybe copied and pasted a brief generated by a popular LLM or legal-tech tool, and failed to check. But no, or at least not only: this one case departs from the usual scenario, in a way that’s more baroque, but also much more loaded.
As surfaced from the Show Cause proceedings, beyond the misuse of AI (which counsel denied, to no avail), counsel had plagiarised a brief from another case, which itself had contained hallucinations that had led to sanctions by a different NY court (it’s also in the database). Pressed on this point, counsel stated that she had sourced the other brief from Westlaw. The court was unimpressed, and sanctioned her and her supervisor with a hefty fine.4
Now, the court mused that failing to check whether a copy-and-pasted brief from another case fits an argument is a worse failing than falling victim to the fluent confabulations of AI. This is a valid position from the standpoint of a third party observer. But a different argument can be made from the viewpoint of the attorney crafting the argument: that one would precisely, intuitively, trust that something that has already been filed in a different case has been checked and is good material.
A common refrain when discussing hallucinations is that they risk slipping into a judgment unnoticed, and then becoming good law before anyone notices; and when retraction, cassation or appeal takes place, it might be too late. But this is not the only way legal propositions circulate: briefs cite (or are inspired by) other briefs; doctrinal analyses rely on case notes; arguments migrate from one filing to the next. Each link in that chain is a point where a hallucination, once introduced, can launder itself into apparent legitimacy; our shared legal epistemic ecosystem can be tainted in many ways.
And this, ultimately, is the danger with AI-generated hallucinations: not necessarily that courts will be swamped in dubious material that needs to be checked (though there is certainly a lot of that), since technology and attitudes (and additional frictions) might eventually reduce the rate of hallucinations. But until we bring this to zero - which I don’t see happening, be it only because AI systems are fragmented - this puts a question mark on a lot of things we assumed were trustworthy. And trust once lost is never fully recovered.
Not a criticism of the author, though; the Michael Lewis book about them, The Undoing Project, makes for good reading.
Which harks back to the Clark and Chalmers’ Extended Mind thesis, for those interested in such ideas.
See also this study published yesterday showing that law students using AI to achieve certain legal tasks did not display the expected drop in performance when later working without AI.
This is also a typical case of attorneys lacking the candour required by the occasion, which certainly coloured the court’s appreciation.
I think this pollution of the epistemic commons gets worse before it gets better with widespread use of agentic research tools.
AI naively cribbing notes from other AI’s hallucinations as grounding means even if the citation accurately summarizes the source (not always guaranteed), the source might already be a prior hallucination anyway.
Damien, in this case https://www.cbsnews.com/colorado/news/colorado-leticia-stauch-conviction-murder-stepson-overturned-juror-biased/ The system failed not because judgment was replaced, but because one of many discrete screening decisions was left entirely manual. Out of hundreds of decisions involved in jury selection, some can be automated to reduce cognitive load without removing human authority. "...we can build or adopt the conditions under which people know when not to use it." The prerequisite problem is decision structure mapping (which machine learning is great at). Before you can offload anything you have to answer: what are the discrete decisions embedded in this institutional process, which are deterministic, which are probabilistic, which are irreducibly human, and what is the authority hierarchy for each?