
Hallucinations in Courts - Much More than you Wanted to Know
What's in a (fake) name ?

(TW: graphs and half-baked data analyses).
As we near the 1,200-case mark for hallucination cases in US courts, I finally took the time to give a look at one aspect of the data that may seem irrelevant or uninteresting: what these fake case names are, actually, and whether they follow any particular rules ?
Fabricated authorities is, by far, the main category of hallucination in the database, followed by false quotes assigned to an existing case or norm, and then misrepresented authorities. While it’s a much cruder form of AI misuse, pure fakes are also easier to check: quotes can be easily tortured or mangled in (more or less) good faith, and misrepresenting authorities is, well, to some extent, what lawyers do (within bounds). And so, to some extent there’s a gradation, where fabrication showcases the hallucinogenic tendencies of LLMs at their purest, while misrepresenting an authority is, at least directionally, closer to ground truth.1
Yet, fabricated case names are not random ! This has been noted now and then, and especially in the past few days when some of you finally nudged me to get a look at this data, viz:
David Timm, on LinkedIn, noted that two distinct cases referred to a “Tucker v. United States” (fake) cite from the Court of Federal Claims, maybe in light of the fact that the court itself found its jurisdiction in the (real) Tucker Act.
Joe Patrice in Above the Law made a point about the distinction between neutral citations and proprietary ones (i.e., the Westlaw or LexisNexis identifiers), pointing out that the latter are an issue at least in dealing with hallucinations: how do you check if something exists if it’s paywalled.
People on the LegalQuants Whatsapp asking good questions.
As we’ll see, they were all on to something. In summary:
Fakes cluster in-domain.
Proprietary identifiers skew fake.
Fabrications lose the true forum.
Same-name collisions are rare but real.
Method, data, etc.
Whenever I input a new case in the database, I send it to a LLM to extract most data points, such as the parties’ names, date, identity, etc. I then review part of the data, harmonise what needs to be harmonised, and manually check important things (such as professional or monetary sanctions).2 Part of the data that’s extracted is the actual hallucination(s), including - when extant - the fake case name, or false quote, or the argument being (allegedly) supported by an existing case.
This is not, and I insist, an exhaustive record of all hallucinations in the cases peopling the database. Not all court documents go through all hallucinations to dissect them one by one - sometimes, there are just too many, and other times judges feel (rightly in my view) that it’s better not to name the fake case, lest someone else cite it down the line. Add to this that LLMs are, hum, sometimes a bit lazy, and would output just a few fields and leave it at that.
Still, that leaves me with a database of 5k+ granular fake citations, fake quotes, or misrepresented authorities, out of which we have about 2,000 distinct fake case names.
I put this data in a Python notebook on Colab, imported good old pandas, and went on to look at a few hypotheses.
In what follows, I often use the non-fake citations in the dataset (non-fake but, again, cited either in support of a false quote, or in a way that misrepresents the actual case) as some kind of comparandum. This is not perfect - after all, these cites were also AI-generated - but, as we shall see, it’s nonetheless meaningful.
Behind the paywall, nobody can hear you check
It is a weird quirk of the US legal system that while it is one of the most open data environments in the world (by far), it also leaves room for legal editors to impose (and benefit) from some restrictions. This is not a dunk: I have nothing against (most) editors, whose tools and offerings I benefit from, but one can nonetheless be annoyed by some artificial limits one encounters in this respect.
And none are more annoying than the proprietary citations they use. There are several reasons for this system (amongst which: not every decision makes it into a reporter, and those take time to collate, requiring a stop-gap measure),3 but there are also alternatives: case name + case number (which are, annoyingly, not unique) + date would suffice to locate most documents without resorting to a proprietary identifier. This is how it’s done in international law / arbitration, and it mostly works out (though citing styles can inflame passions, as is well known).
Anyhow, as Patrice pointed out, the original problem with proprietary citations - that you can’t access a case if you don’t have access to the vendor’s products - is now compounded by the hallucination issue: you can’t even check whether a case exists if it’s Westlaw- or LexisNexis-tagged, nor can you easily map it to an existing case without further details (such as a date to go with the name).
But is that an actual problem in the database ? Yes it is. In total, around 20% of all fabricated authorities I managed to collect have a proprietary identifier, a share that appears to be stable since last year.
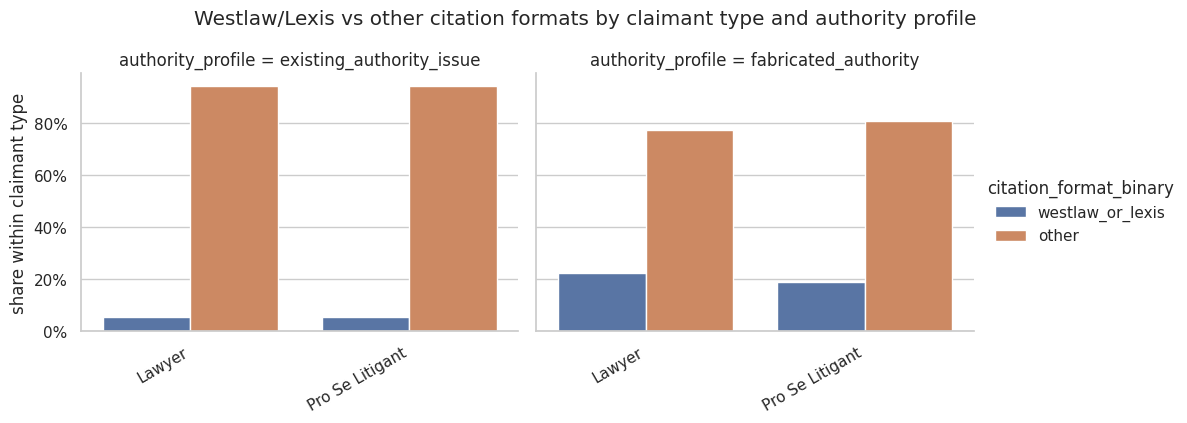
What’s even more interesting - visible in the graph up there - is that most proprietary identifiers in the database originate in fake case names - and not when what is cited is an existing authority, which mostly rely on neutral identifiers.
To some extent, this is an artefact of the boundary between “fake” and “genuine” authorities and stems from insufficient training data: many “fake” cases are deemed as such by courts precisely because they associate an existing name with the wrong identifier. But it could also be that when looking for a precedent to add to a losing argument, LLMs go more naturally towards a proprietary identifier for some reason.
That reason could be that the training data grants more weight to proprietary identifiers in some contexts or for some case names, such that it contributes to the authority that comes with style (i.e., citing prestigious authorities). But then, what a coincidence that it makes that authority of style even harder to check !
The fruit does not stray far from the poisoned tree
Here is a list of the fabricated authorities that led to sanctions in Mata v. Avianca. Can you spot a common thread ?

In case this is not obvious, nearly all these fake cases relate to airlines or are aviation-coded. To recall, Mata v. Avianca was originally a tort claim from an airline passenger, so there is no a priori reason why it would rely on aviation-related cases. A perusal of the offending brief indicates that many of these cases were cited for jurisdictional arguments related to the Montreal Convention, which provides some backing for the citation to airline cases - but it’s also possible that a brief generated by ChatGPT would veer towards discussing such matters when briefed in an aviation case.
My point, however, is that LLMs commonly return to similar themes and authorities, including when they hallucinate - i.e., they do not stray far from the fundamentals of the case. Which is good in general but, when it comes to inventing fake case names, means that such case names are likely to cluster around something that looks like the parties’ names.
I could not check this to the fullest extent, but what I could do is look at whether parts of a case name end up being repeated in the fake authorities.4 The example here would be cases against the United States eliciting hallucinations of the form “X v. USA”, or complaints against a given “Board” would lead to fake cases involving other such “Boards”.
And indeed, when looking at the data, this kind of clustering is surprisingly common. Simply looking at whether a party’s name makes it into the fake authority (or a real, but misused authority) matches with around 5% of all cites. The most common name parts in this respect are expected:
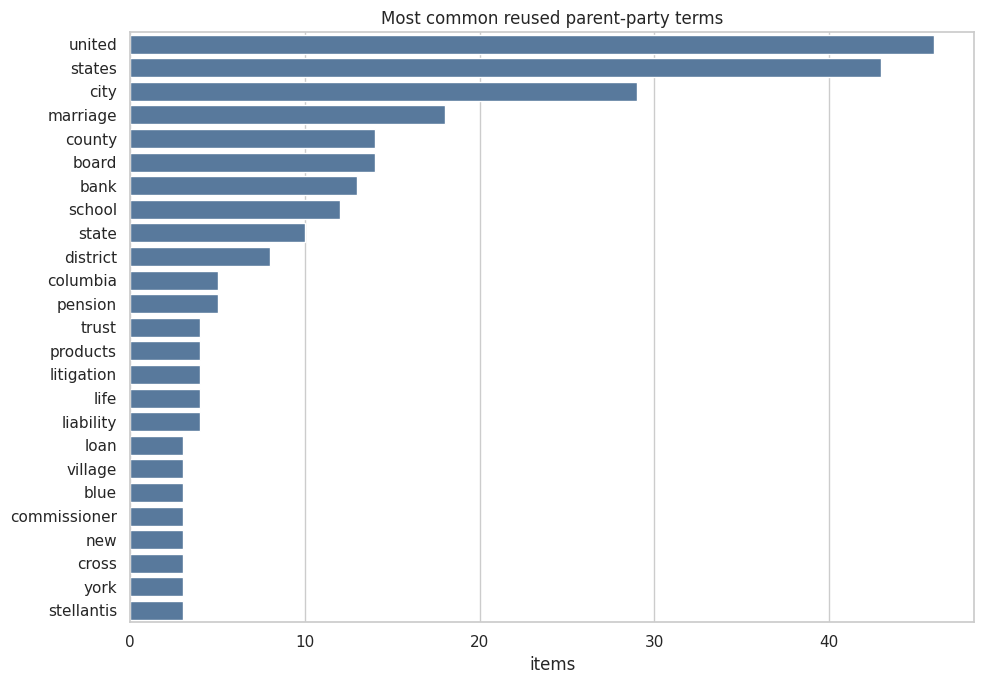
And again, this is a deliberately crude measure; because it only catches exact token reuse and misses semantic/domain resemblance, it should be read as a floor.5 The example from Mata v. Avianca above would not appear in that figure, let alone the many similar examples in the dataset of fake cases I managed to eyeball.
But as always, there is something deeply human there. It makes sense that when litigating a case in a particular field, the precedents at hand and the form of citations thereof would take some distinctive forms: bankruptcy cases being “in re:”, administrative law cases involving public law parties, etc.
Yet, beyond this, one strongly-held intuition6 I have is that, everything otherwise equal, one would be tempted to cite within one’s field or subfield - e.g., a mining investor in an investment arbitration case citing authorities from other mining cases, even on unrelated matters. This is partly strategic: these same-field authorities might be relevant and helpful to your case for other reasons, and by signalling them on unrelated matters you increase the chance that the adjudicator will look at them. But this is also aesthetic, situating your case within a community of cases, rather than as something purely contingent.
Which is to say, you would expect LLMs to reach for the authorities that are closest semantically, because humans would do too.
Somewheres and Anywheres
Another illustration of LLMs reaching for the familiar is visible in the provenance of fake cases: in federal courts, they are more likely than baseline to be local cases from state courts, including when compared to genuine (though misused) cases.
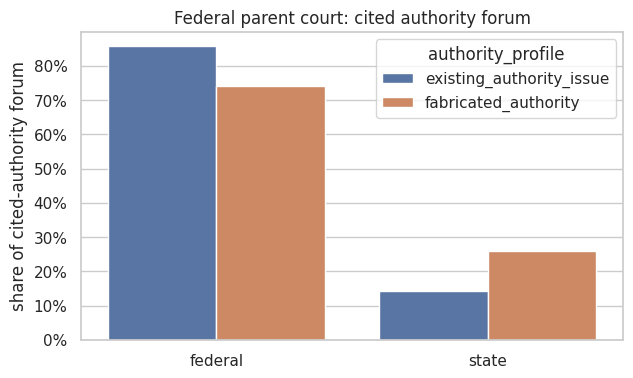
In other words, an LLM somehow retrieving a real case drags its true (federal) forum along 86% of the time, because the case was decided somewhere federal and that fact travels with it. A fabricated case has no true forum, so when the model assembles a plausible-looking caption it reaches for state-reporter surface forms, likely on account of matching the district court’s location: the fake reaches for state surface forms because pattern-matching works from where the court physically sits, not from any actual reasoning about jurisdiction.
And indeed, disaggregating the numbers further and looking at state court hallucination cases, we see that models mostly stay within the same state when making up a fake case.
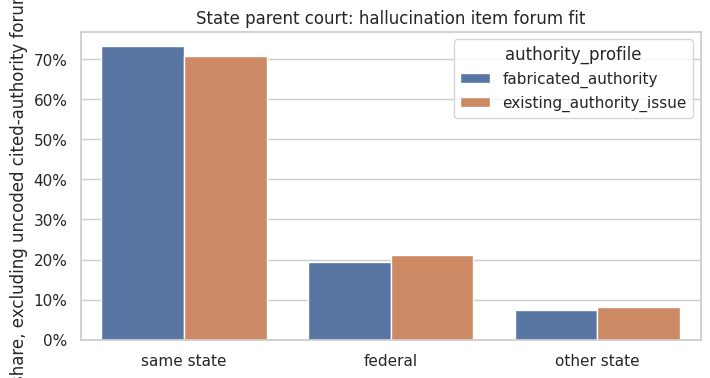
Once again, just like their human counterparts, LLMs keep to the familiar.
Repeated case names
While this analysis was partly prompted by David Timm’s pointing out to two distinct cases citing the same fake authority, there are very few further examples in the database:
“Miller v. United States, 532 F. Supp. 2d 1365 (E.D. Ill. 2008)” was cited in Poole v. Walmart, while “Miller v.United States, 2009 WL 1532834 (D. Ariz. Apr. 30, 2009)” was cited in Turnage v. Kennedy.
“McNeil v. United States, 2015 WL 3866233, at *1 (D. Or. June 22, 2015)” is cited in Nemec v. Alao, while “McNeil v. United States, 508 F.3d 674 (10th Cir. 2007)” is cited in Carter v. UZGlobal.
What these case names have in common, of course, is that they are very common names on both sides of the “v.”. And indeed, there are countless “Miller v. USA” and “McNeil v. USA” cases out there, but none with these identifiers (which is what led them to be labelled as a fabrication).
And so, what do we learn from all this ?
The main point, I made it at the outset: the fakes aren’t random noise. They are an issue in the sense that they are false, not in the sense that they are meaningless. And that meaning, just like human lawyers, they take it from the case around them: the parties, the forum, the subject-matter, the legal vocabulary, the citation style, and the need for which they have been brought onto the page.
A great deal of legal authority, we already mentioned, already rests on surface cues: the right caption, the right court, the right authority, the right name at the bottom of the page. Hallucinated citations exploit that economy of trust. They work because they are banal, and look like the kind of thing a normal legal process would naturally produce. Looking at a few hundred case names just gave this a bit more empirical backing.
Although, I would argue, a better view is that LLMs always hallucinate everything, it just happens that most hallucinations are “true”, as in, coinciding with ground truth.
If you are thinking: “but, LLMs hallucinate, maybe there are hallucinations there?!”, you might be right. My only defense is that closed-ended tasks going through structured output hallucinates less in general, and I recently passed the entire thing (one by one, of course) through another LLM to spot errors (plus some mechanistic checks), and the few mistakes that surfaced were nearly all human in nature.
Going further, I could check every fake citation with a LLM to try to match the observation we had here with Mata v. Avianca, but my research budget is not that extensive.
To test whether this was merely an artefact of party names being repetitive within the same kinds of cases or courts, I shuffled the fabricated authorities against other parent cases within the same parent forum. That shuffled baseline clusters below 1%, while the observed exact-token overlap sits above 5%. In other words, even this very crude measure captures a real local leakage from the parent case into the fabricated authority.
If only someone had authored a doctoral thesis trying to prove empirically such hunches !
Excellent article. It reminded me of when I found a hallucinated case that change the first letters to get Casserole Tech v. Caserage Labs apparently from a real Laserage Tech v. Laserage Labs. https://midwestfrontierai.substack.com/p/plumberslocal-no-75-v-morris-plumbing
Also, a quote from Utah agreeing with your point about common surname v. U.S. "There are thousands—I was going to say 'a thousand,' that’s an exaggeration—there are a bunch of cases in Utah called 'State versus Carter. 'Quite by accident, we cited the wrong State v. Carter. That’s our error. It doesn’t really support the proposition.'" https://midwestfrontierai.substack.com/i/174305891/utah-show-cause-ai-ok-misuse-not
In LLMs, the only meaning a term has is the (condensed) set of words with which it co-occurs. Words operate as if they have similar meaning when they occur in similar contexts. LLMs have no way to represent anything other than the context, so, as you point out, fabricated words (in your analysis, citations) are going to be more closely associated with the context of the rest of the document. Thanks for this great start on understanding hallucinations.