
AI & Law Stuff #2
Laws, insurance, and the perennial question of who's the author

AI laws are coming for you
Most of us live in states and societies that live, or profess to live, under the rule of law. Leaving aside any precise definition thereof (which I would not be qualified to offer anyway), one non-controversial aspect of this is that “the law” is what we turn to in many situations or circumstances, the proverbial trees that protect us against the Devil, the first port of call if one encounters an issue, a challenge, etc.
In turn, this has the consequence that, when facing a “new” social or economic development, one has not to wait long for the shouts to do something about it, to fill the “legal gap”, lest something terrible happen.1 On both sides of the pond, entire industries of legal tinkerers (me included), at various stages of the process, will brainstorm something, anything that could touch on the “new” issue, be it to study it, criminalise it, or at least to regulate it, make sure it properly enters the categories of the prevailing legal apparatus.
More law is, by definition, always good; a “legal gap”, always a tragedy.2 And the urge to legislate often means half-baked norms that fail to understand their subject-matter, add to what already exists, or seek to govern things that have often been left alone for a reason.
All this to preface the fact that, two or three years down the line of generative AI’s emergence into our lives, the lawmaking process to deal with this is shifting into full gear.
On his Substack, Dean Ball has recently written on the “patchwork” of legal regimes that may be the result of the various efforts throughout US legislatures, rightly showcasing the confusion of many legislators as to what exactly they intend to do beyond headlines.
But one in particular might be worth watching, because it applies to the legal profession and arbitrators (and thus meets all my interests). California Senate Bill 574, set for a hearing on January 20, offers a grab-bag of prohibitions: it obligates counsel to sanitize their output of hallucinations, forbids the entry of confidential data into ‘public’ AI systems, and enjoins arbitrators from delegating decision-making or relying on AI without disclosure
This bill illustrates a lot of what I was saying in introduction:
Much of it adds to what already exists: the legislative counsel’s digest recounts that attorneys on record are already obliged to certify that any brief they file is warranted. The 48 cases from the hallucination database hailing from California show that judges have been perfectly able to use existing requirements to sanction lawyers that file briefs with hallucinated material. Likewise, arbitrators are already prohibited to delegate decision-making - deciding is the very point of them being appointed as arbitrators.
Confusion as to the tech side: The confidentiality mandate, which echoes very common (if often misplaced) fears by the legal community, is incredibly unclear in its scope. If the fear is that confidential information is being used to train future models, most LLM providers swear this won’t happen unless you opt in. And if it’s a question of data leaving one’s local system to get onto an outside server, then all “drive” solutions are suspicious too.
Vague terms and scope are the result of a pure desire to legislate at all costs: while the bill’s definition of a Gen-AI system3 is not the worst I have seen, there is no indication as to what a “public” Gen-AI system is meant to be. Likewise, counsel are required to take “reasonable steps” to ensure the accuracy of the material they produce, without being clear as to what this entails.
Trying to govern things best left alone: the mandate that arbitrators should not rely at all on Gen-AI without disclosure will likely sit oddly with the secrecy of the deliberations. We do not permit parties to inspect the mental processes of adjudicators for good reason; it is not obvious that the “black box” of a neural network is functionally different from the opaque, often chaotic internal monologue or brainstorming of a human arbitrator. And as in many respect, legislating away AI use (as this obligation will certainly do) will simply result in concealed/shadow use of AI instead, making things worse.
Just like many other AI-related bills in the past few years, it’s likely this one won’t go far. And while not particularly detrimental in itself, its real interest lies in how clearly it exposes the lingering confusion - conceptual, technical, and institutional - that still surrounds attempts to govern generative AI by law.
The House Always Insures First
Where laws stop, insurance often takes the baton, and this is likely to become a big topic in the coming months.
Indeed, an entire history of the deployment of AI (and other technologies before it) could be told through the lens of the insurance industry, and the constraints it put (sometimes legitimately !) on adoption and use. In a sterling piece on AI and radiologists at Works in Progress, Deena Moussa wrote that:
And when autonomous models are approved, malpractice insurers are not eager to cover them. Diagnostic error is the costliest mistake in American medicine, resulting in roughly a third of all malpractice payouts, and radiologists are perennial defendants. Insurers believe that software makes catastrophic payments more likely than a human clinician, as a broken algorithm can harm many patients at once. Standard contract language now often includes phrases such as: ‘Coverage applies solely to interpretations reviewed and authenticated by a licensed physician; no indemnity is afforded for diagnoses generated autonomously by software’. One insurer, Berkley, even carries the blunter label ‘Absolute AI Exclusion’.
Without malpractice coverage, hospitals cannot afford to let algorithms sign reports.
Seb Krier made the same point more recently: adoption of AI lags even though AI becomes increasingly better at many tasks, because the agency of AI (which makes it so useful) is all the more harder to insure against. Insurers have warned that all the ingredients are there to get big insurance-based litigations that centre around the role of AI, especially in cases where contractual norms predate its emergence (but might still apply to it).
And this includes legal malpractice insurance. Weeks ago I was tagged in a LinkedIn post:

As far as I am aware, we are yet to see any verdict on this subject, but lawyers and counsel who use AI - and a majority likely do - may lend attention to this potential development.
But more generally my point here is that the insurance sector often quietly answers a question that law often fumbles: not who is at fault in the abstract, but who is allowed to act, and under what conditions.
Did an AI write this ?
Last week when tallying up Australian cases involving hallucinations, I stumbled on this case, a 2025 decision of an Australian court, where a rejected PhD applicant argued - among other things - that a shortlisting email was AI-generated and that this fact mattered legally. What struck me in particular is this passage:
[Plaintiff] asserts, based on her specialised academic and career expertise, that Associate Professor [Defendant]’s email was generated using artificial intelligence. She submits that the email exhibits an “overexcited personality associated with ChatGPT at that time”.
[…]
According to [Plaintiff], the indications that the message was drafted using artificial intelligence were the excessive number of exclamation marks; no less than three exclamation marks were used after the word ‘congratulations’ and a fourth exclamation mark appears at the end of the body of the message; and the use bolded text, usually associated with headings, within numbered paragraphs and bullet points.
[…]
Having read the email in the form sent to [Plaintiff] and to the other shortlisted candidates, I am unable to infer from the use of exclamation marks, bold text, and the failure to use semi-colons in a list in preference for bold text that the message was generated using artificial intelligence or the extent to which artificial intelligence was used in its generation.
While this made me smile, it touches on something real: several times per day, you and I (or at least I) are wondering: was that penned by AI ? But few of us (or, again, at least I) wonder what we should do with this information, if we had the correct answer.
To be sure, the heuristics4 employed here did not strike me as accurate (on the contrary, I’d say the use of exclamation marks, and the glaring failure to use semi-colons in list, denote (terrible) human choices). Better heuristics likely exist, and I am indebted to this piece from Holly Robbins in particular.
But the ground issue here is that we are trying to resolve a Yes or No question to a situation that is not necessarily a binary (writers may include generated output in various parts of their text, including mid-sentence: it’s not that the author used AI, it’s that AI bled into the writing process), with tools that do not lend themselves well to this kind of classification (i.e., all of us now know about antithetical construction, “it is not X, it is Y”, but we likely overshoot in assigning all constructions of this type to AI, and this signal might taper off as model-makers try to counteract it).
And then the question of what to do with our verdict is even more interesting. As a preliminary point, I’d say there are some categories of text where the presence of the human is the very point. This remarkable piece in particular argued:
Or take blog posts. The whole point of a blog post, to me, is that a human spent time thinking about something and arrived at conclusions worth sharing. It’s valuable because, of all the things they could have written about, they chose this one and spent real time on it—and because it reflects their actual reasoning process. But if I suspect a post is LLM-generated, I disengage, even if the content is accurate. If it’s just some fluent summarization, it’s no different from me just asking ChatGPT for something. And I can easily do that. Why should I read this particular blog post?
While this puts the issue in utilitarian terms, there is also some kind of emotional valence involved here: one feels betrayed to discover that a human they trusted to provide information, from one thinker to another, has actually delegated it to AI. Another consideration is in terms of credibility, as we see in the hallucination database when experts are caught filing AI-generated outputs.
By contrast, other types of text do not necessarily need the human: summaries, reports, some kind of routine analyses. In fact, in many respects such texts may be better off written up by AI, in terms of accuracy, lack of idiosyncrasies, utilitarian value, etc. Which begs the question of whether they should even be read (a topic we dealt with last week), but one has to remember that producing text has other roles than being read, such as preserving a record, signalling compliance, or acting as a performative shield against future liability.
This offers a key. If we take the ‘origin’ axis (Human vs. AI) and cross it with a ‘consumption’ axis (Who is this text for?), we can map texts as follows:
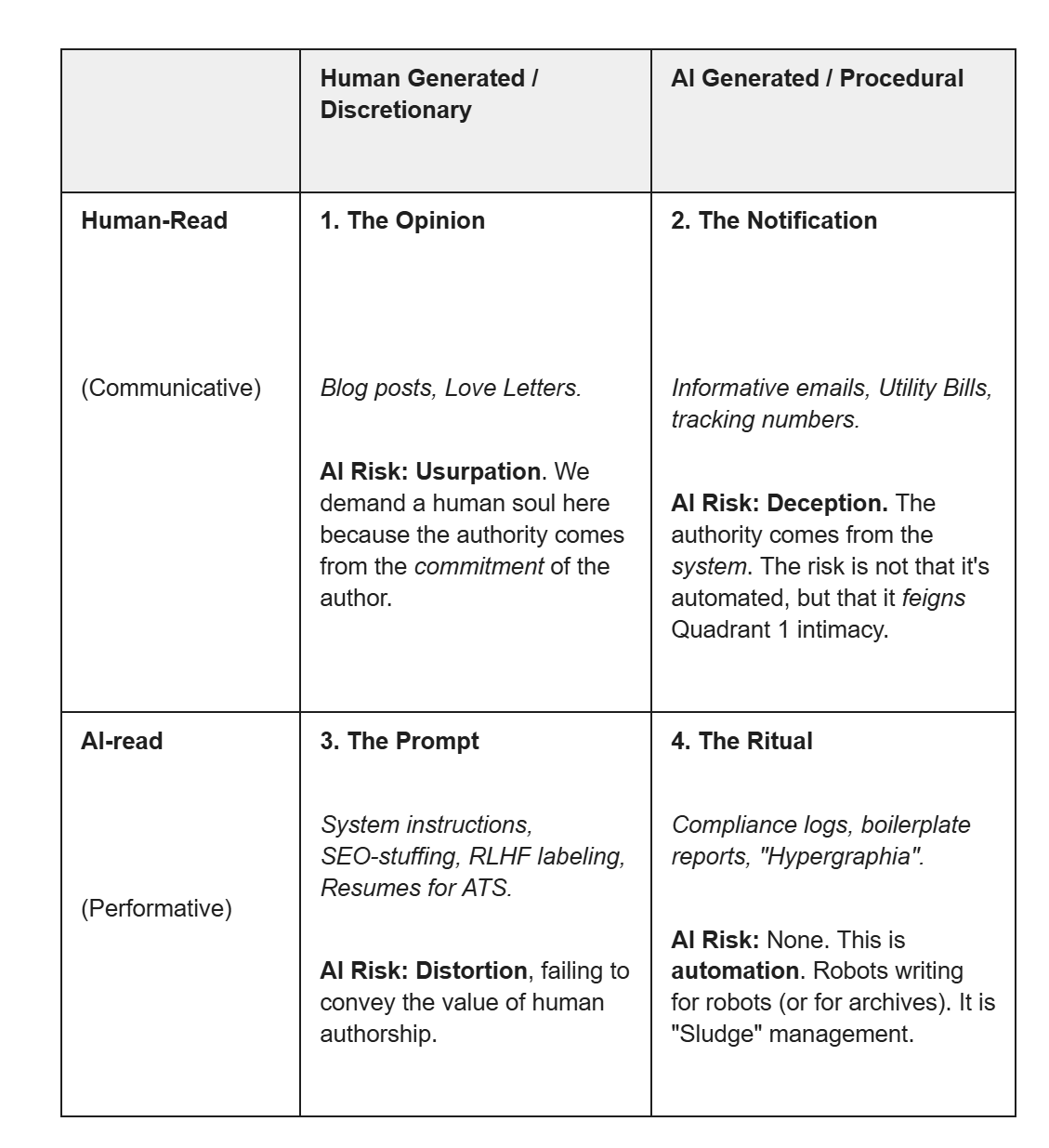
This half-baked categorisation does not cover all, or even most texts, but it might help navigate this question by making us reflect on whether we should care that something has been written up by AI. Most contemporary anxiety about AI writing comes from applying Quadrant 1 norms to texts that belong structurally to Quadrants 2–4.5
A better question is then not whether AI was used (we’ll likely never know), but whether we are demanding human authority from texts whose function does not require it.
Of course, nothing new here, and on this subject nothing beats the French author who bawdily described this as an “envie de pénal”.
And nowhere is it truer than in my own field of international law, where you would be hard-pressed to find anyone confessing that, maybe, there are any downsides with international norms, treaties, etc.
I.e., “an artificial intelligence system that can generate derived synthetic content, including text, images, video, and audio that emulates the structure and characteristics of the system’s training data.”
As an aside, the technology to detect AI is, as far as I am aware, a work in progress. Early “AI-detectors” were terrible, but I heard that this has become better, and will certainly benefit from the move to watermark some AI outputs. However, it is very likely that this will develop as for computer security or cryptography: a perpetual game between offense and defence, such that dedicated actors could always prove/disprove use of AI.
Meanwhile, we ignore the (maybe more relevant downstream) situation of Quadrant 3: humans voluntarily changing/adapting their syntax and nuance just to be legible to a machine.
I do agree that we shouldn't put so much the blame on AI made summaries or paragraphs when they are published by authors. Alright.
But ... I've seen lots of summaries/synthesis that miss a crucial piece of information or use one opinion on a subject matter and doesn't take into account the other one. I always disclose such use whenever I send an AI made summary that I didn't have time to check and edit myself.
For another example of the US practice of creating patchwork legal regimes, see US privacy protection.